
chat channel
joafip users mailing list
forums
Les créations, mise à jour, effacement sont faites à la sauvegarde dans le fichier. Le process de sauvegarde visites les objets du graph à partir de l'objet racine.
A la visite, pour chaque
objet compare à l'état à lecture dans le fichier:
-
Create: si l'objet est nouveau (pas d'état de
lecture dans le fichier),
alors il est sauvé dans un nouvel enregistrement dans le fichier.
- Update:
si l'état de l'objet à changé alors son enregistrement dans le fichier
est mis à jour. Cela inclut le changement d'objets référencés.
- Delete:
quand un object n'est plus référencé par d'autres objets, alors
l'enregistrement associé devient "candidat au nettoyage" ou "à
detruire" ( deux cas à cause de la possibilté de cycle dans le graphe
d'objet)
C'est ici que les proxy
sont utilisé
pour ne pas gaspiller de mémoire, pas de vérification s'il y a assez de
mémoire, mais cré plutôt un proxy pour economiser de la mémoire puisque
ce dernier ne référencera aucun autre objet tant qu'il n'est
pas
accédé.
L'objet racine est le premier à être crée en mémoire.
L'accés à un object est toujours fait en navigant à partir de l'objet
racine, un object proxy est toujours retourné.
L'interception des appels aux méthode provoque le chargement de l'état
de l'objet par lecture du fichier.
Comme les instance de
collections sont des graphes d'objets, le même mécanisme est appliqué.
Mais certaines implémentation de respectent pas les conditions
sur les classes imposées par joafip. Ces conditions sont imposées par
l'utilisation des proxy..
A cause de ces condistions joafip a sa propre implémentation des collections.
Mais aussi parce que
l'implémentation
de JOAFIP permet une "lazy load" plus efficace (par exemple, le cas des
implémentatio native java de HashMap et de HashSet -
même
choses pour les implémentations GNU Trove).
Depuis la version 2.0.0, JOAFIP peut invoquer les méthodes de sérialisation implémentées dans la classe, ainsi il peut persisté les implémentations de collections natives, mais ce n'est pas le mieux pour une bonne gestion du lazy load.
Ci-après une description de comment sont persistés les objets
dans le fichier.
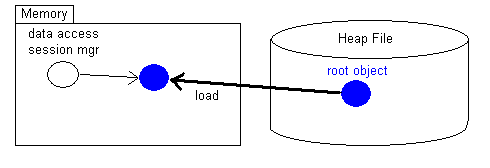
A l'ouverture de la session d'accès aux données, l'objet racine est
chargé en mémoire. Le rôle de l'objet racine est de référencer les
autres objets persistés.
Le gestionnaire de session d'accès aux données a deux methodes pour
gérer les objets persistés référencés par l'objet racine.
Pour pouvoir persister un graphe d'object il doit être référencé par
l'objet racine.

La
fermeture de la session d'accès aux données, avec l'option de
sauvegarde, fait persister le graphe à partir de l'objet racine.
Après
cela, relacher (déréférencer) les objets, il n'y aura plus d'objets en
mémoire ( après passage du garbage collector de la JVM ! )

Pour accéder à nouveau il n'y a qu'à ouvrier une session qui chargera
seulement l'objet racine.

La requête de l'objet o1 à l'objet racine qui est djà chargé
provoquera une chargement automatique de l'objet o1.

Ci-dessous un exemple .d'opération sur les objets:
Le proxy permet le chargement automatique de l'état de l'objet puisque une méthode de l'objet a été appelée.
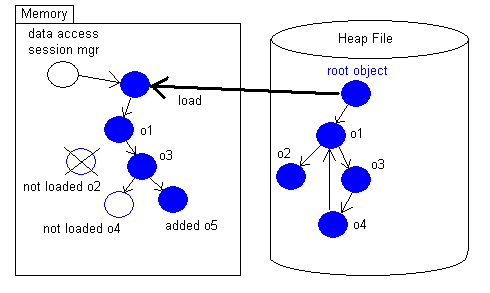
A la suauvegarde de la fermeture de session d'accès aux données:
l'enregistrement pour o1 est mis à jour car l'état de o1 a changé
l'enregistrement pour o3 est mis à jour car l'état de o3 a changé
o5 est créé dans le fichier
l'enregistrement o2 sera libéré par le garbage collector de joafip
Après cela plus d'objets en mémoire.

Il
y a le cas où les références entres objets ne changent pas, mais la
modification d'un champ primitif provoque la mise à jour de
l'enregistrement dans le fichier.
Partant d'un graphe d'objet sauvegardé dans le fichier.
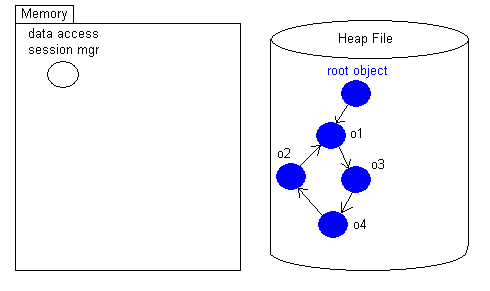
puis lecture de l'objet racine

Et faire que l'objet racine ne référence plus l'objet o1 ( pas exemple
via quelque chose comme rootObject.setO1(null) )

Puis fermeture de session avec sauvegarde:
l'object
o1 devient un candidat au nettoyage. Le garbage collector aura
à
verifier que o1 dans le fichier n'est pas attaché à l'objet racine par
un chemin de référencement partant l'objet racine.

